Improving continuous fuzzing of Liblouis
In collaboration with the Liblouis maintainers and the Open Source Technology Improvement Fund (https://ostif.org)
Summary of engagement
In this blog post we describe efforts we did pro bono for improving continuous fuzzing of the Liblouis project. We will cover how we increased code coverage from 20% to 80% and show how we measure the state of a fuzzing set up using the open source tool Fuzz Introspector. We will also show how we tracked progress of the work using https://introspector.oss-fuzz.com
The goal of this engagement was to improve the fuzzing efforts in Liblouis and ensure that it is continuously analyzed by OSS-Fuzz. Liblouis is an open source braille translator with an extensive set of features, and Liblouis was initially integrated into OSS-Fuzz in early 2021 but had since then had little progress in terms of expanding fuzzing to cover a lot of the codebase.
Prior to the engagement, the Liblouis team had a fuzzer with extended capabilities for targeting the translation code. However, this fuzzer did not run continuously on OSS-Fuzz and the fuzzer had some limitations that hindered it from easily integrating with OSS-Fuzz. To overcome this we extended this fuzzer with new features to migrate it into OSS-Fuzz. We, furthermore, added an additional fuzzer as well as a fuzzing dictionary to achieve optimal code coverage.
The fuzzers achieve a code coverage of around 80% and a static reachability of around 93%. However, we predict the code coverage will go up after the initial set of issues found by the fuzzers are fixed and the fuzzers have run for longer periods of time.
The fuzzers have now reported six issues in total, three of which are memory corruption issues. Each of the issues found are relatively early in the control-flow of the fuzzers, and for this reason we find it likely that more issues will be found once these issues have been fixed as they are likely blocking the fuzzers from progressing.
Liblouis fuzzing set up
In total, throughout this engagement we added two fuzzers to the project and a dictionary that would be applied to both of these fuzzers.
The first fuzzer fuzz_translate_generic is available here https://github.com/liblouis/liblouis/blob/master/tests/fuzzing/fuzz_translate_generic.c and has the purpose of supplying fuzzer-seeded data to liblouis in two sources. First the table used for rules-based translation is seeded by fuzzer-generated data, and the input to translate is also seeded with fuzzer-generated data. The most security critical part of Liblouis is in the input translation and this fuzzer is capable of exploring a diverse set of translation states since the fuzzer also seeds the table used for defining translation rules.
The second fuzzer fuzz_backtranslate is available here https://github.com/liblouis/liblouis/blob/master/tests/fuzzing/fuzz_backtranslate.c and has the purpose similar to fuzz_translate_generic in terms of seeding the table for translation rules with fuzzer-generated data, however, in this case the fuzzer executes a back translation rather than a forward translation. In this sense the fuzzers are similar in nature.
Finally, we added a dictionary to each of these fuzzers which is accessible here https://github.com/liblouis/liblouis/blob/master/tests/fuzzing/fuzz_translate_generic.dict This dictionary captures all of the Opcode names used by liblouis for translation table construction which are identified here https://github.com/liblouis/liblouis/blob/cdc252cd21ca772e1a03ff88b353cff6e93e96be/liblouis/compileTranslationTable.c#L157-L276.
We extended the existing build script used for the OSS-Fuzz set up to include these fuzzing artifacts, which is accessible here: https://github.com/liblouis/liblouis/blob/master/tests/fuzzing/build.sh
Assessing the completeness of the fuzzing
A central question when fuzzing a project is how well the project is fuzzed. In this section we will cover this for Liblouis by using various tools and techniques to understand the completeness of the fuzzing suite.
To understand this we will use the project data shown by https://introspector.oss-fuzz.com which neatly visualizes data from the OSS-Fuzz set up. The specific profile page for Liblouis is here https://introspector.oss-fuzz.com/project-profile?project=liblouis.
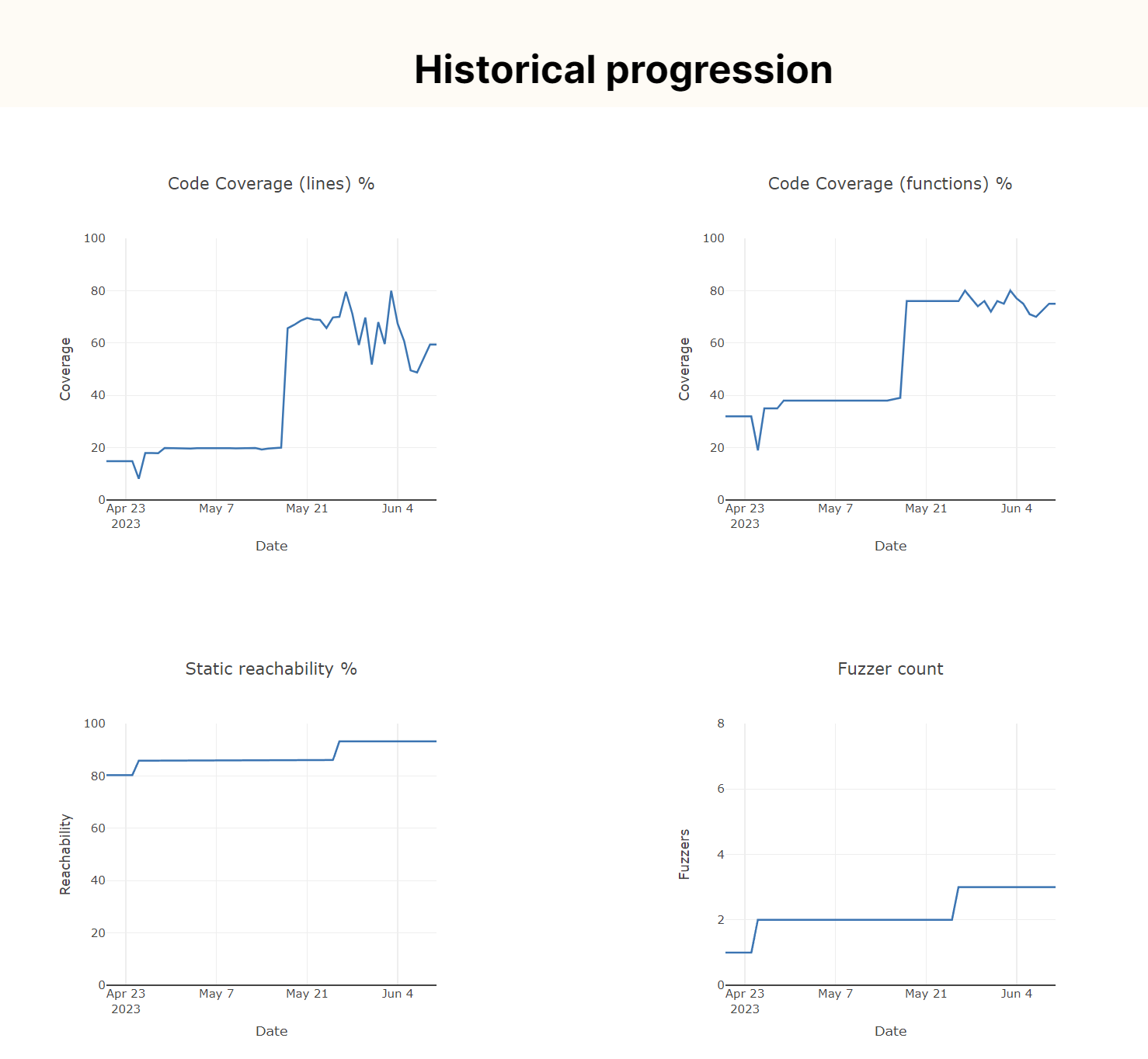
The four graphs above show a set of time series for certain fuzzing measurement units. Specifically:
- Upper left “code coverage (lines) %” indicates how many lines of code as a percentage of the total Liblouis codebase are covered at runtime by the fuzzers.
- Upper right “Code coverage (functions) %” indicates how many functions as a percentage of the total functions in the Liblouis code are covered at runtime.
- Lower left “static reachability %” shows the total control-flow reachability determined by static analysis for all the fuzzers in the project. The unit in this case is the percentage of functions in the codebase.
- Lower right “fuzzer count” shows the total fuzzers of the project.
The first fuzzer that was added as part of this engagement was integrated April 25th. We can, however, observe that the project already had a high level of static reachability (around 80%) but fairly low code coverage (around 20%). The reason for this is that the existing fuzzer in the Liblouis codebase already had a large control-flow scope, however, failed to actually execute all of this code at runtime.
As we can see from the plots, the fuzzer added on April 25th had a minor positive impact on code coverage and static reachability. However, on May 18th the code coverage jumped from 20% to 65%. Interestingly no new fuzzer was added at this point, however, this is the exact date that we added the dictionary as described above. As such, the dictionary caused a significant jump in code coverage.
On May 26th, a new fuzzer was added and this caused another jump in code coverage from around 69% to 79%. The fuzzer added in this case was the back translation fuzzer described above.
Since May 27th there has been volatility in the code coverage achieved by the fuzzers. The reason for this is likely that the Liblouis library contains some stateful attributes. The effect of the statefulness is that when multiple runs of the fuzzer entrypoint function are run the ordering matters, and code coverage is collected by running the generated corpus by way of the fuzzer. The coverage collection does not guarantee the same order for each code coverage run, which causes the volatility in code coverage %. A note here is that this also impacts the determinism of the fuzzer, so reducing the statefulness of Liblouis is an important next task. To this end, we conclude that the current state of fuzzing is fairly high, around 80% and the static reachability is at 93% which is also an impressive state. The next logical step for the fuzzing work is to fix the issues and let the fuzzers run for a short while before expanding to more fuzzers covering the remaining 20% of lines.
Identifying the missing gaps
In order to identify the next areas of code that should be fuzzed we will access the Fuzz Introspector report linked to at https://introspector.oss-fuzz.com/project-profile?project=liblouis.
The Fuzz Introspector report is available at https://storage.googleapis.com/oss-fuzz-introspector/liblouis/inspector-report/20230610/fuzz_report.html and shows various program analysis details of Liblouis. We will use this report to identify what functions in the code that reach a lot of code but are still uncovered. In this case, we will use the “Project functions overview” to identify targets that have a lot of complexity but no code coverage. We can access this table here:
https://storage.googleapis.com/oss-fuzz-introspector/liblouis/inspector-report/20230610/fuzz_report.html#Project-functions-overview
Following sorting of the “Undiscovered complexity” and “Func lines hit%” we we get the following set of functions:
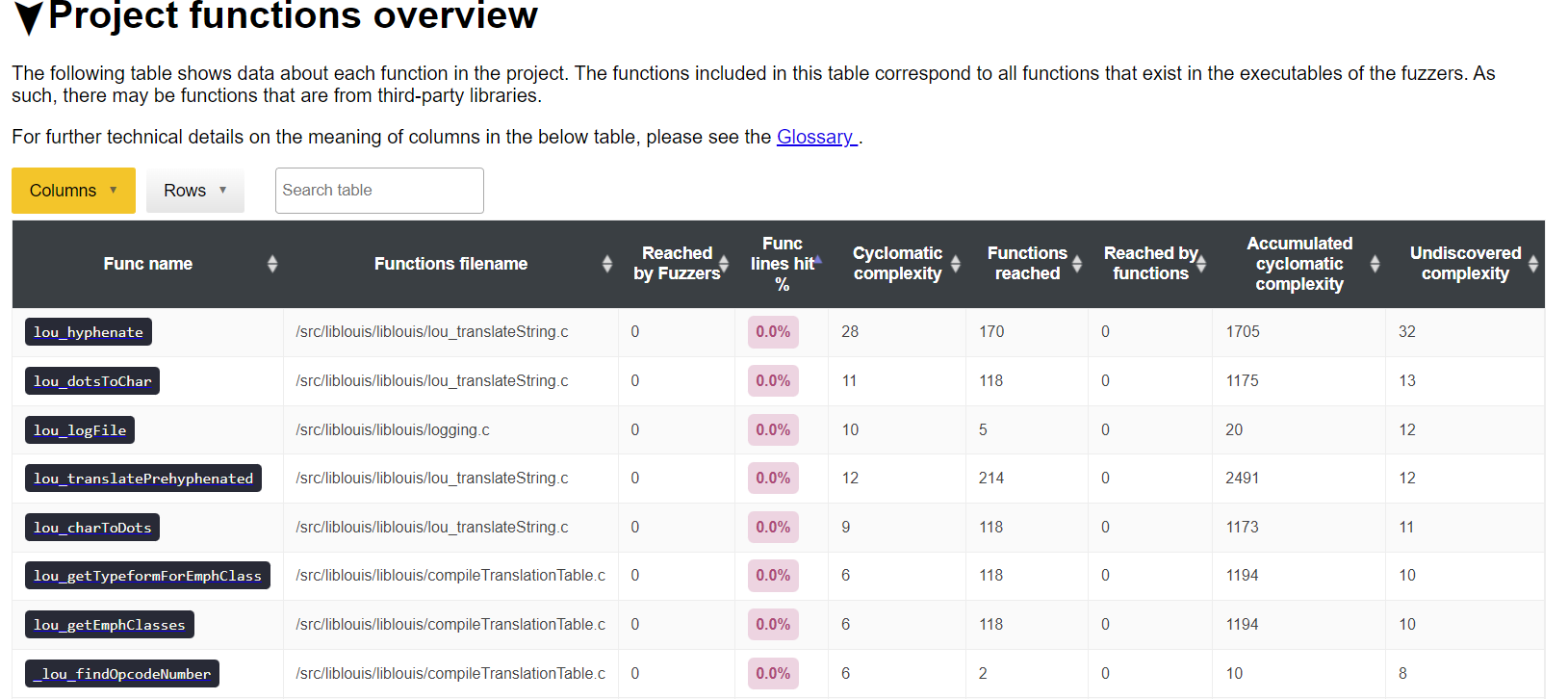
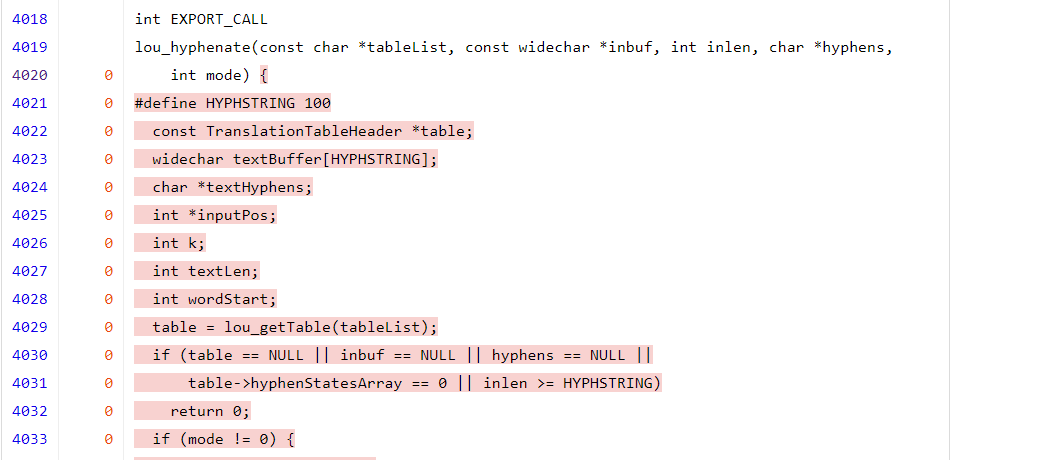
The Fuzz Introspector conveniently links to the code coverage report to the functions locations by clicking the name of the function in the table. We can confirm this by for example following the link to the lou_hyphenate function, which links to https://storage.googleapis.com/oss-fuzz-coverage/liblouis/reports/20230610/linux/src/liblouis/liblouis/lou_translateString.c.html#L4020 and we can confirm this indeed has no code coverage:
We can use this Project functions overview table to show details about all functions in Liblouis, and this conveniently highlights which are the missing functions with code coverage, as well as additional metrics for each function.
The list in the above figure are the primary targets we would suggest adding fuzzers for, or at least analyze if they are suitable, as these are the functions with most accumulated complexity in their control-flow graph which has the least amount of code coverage. Once they have been covered Liblouis will get close to having 100% code coverage.
Conclusions
In this short engagement we improved the continuous fuzzing set up of Liblouis by way of OSS-Fuzz. The fuzzers achieve code coverage of around 80% and have reported a total of six issues so far. We expect more issues to be found once the initial batch of issues have been fixed.
To assess the completeness of the fuzzing we used the public data published by OSS-Fuzz on introspecting the OSS-Fuzz projects, which is available here for Liblouis: https://introspector.oss-fuzz.com/project-profile?project=liblouis We can observe the progress in the fuzzing and an interesting observation during the engagement was the impact of dictionaries for the fuzzers. Specifically, adding a dictionary increased code coverage from 20% to 65% for a single fuzzer.
Finally, using the Fuzz Introspector reports available at https://introspector.oss-fuzz.com/project-profile?project=liblouis we are able to identify the important missing targets for the fuzzing suite and recommend the Liblouis maintainers to prioritize these functions for further fuzzing work.